在编写robots.txt文件之前,首先我们需要了解什么是robots.txt文件。robots.txt文件是指定给搜索引擎spider程序的收录规则。一般情况下搜索引擎spider程序自动访问互联网上的网站时,会首先检查该网站根目录下是否有robots.txt文件,这个文件用于指定spider对网站的抓取范围,如果没有robots.txt文件或robots.txt文件为空则表示允许spider抓取网站上所有内容。
其次我们需要把robots.txt文件放在正确的位置。robots.txt文件应放置在网站根目录下,例如何昌全博客(https://www.hechangquan.com/)相应的robots.txt文件的地址为:https://www.hechangquan.com/robots.txt
那么,我们开始学习正确的robots.txt文件编写规则。
正确的robots.txt文件用法举例:
1、禁止所有搜索引擎抓取网站的任何部分
User-agent: *
Disallow: /
请注意!有一些新手朋友正是误把以上robots规则理解为允许所有搜索引擎抓取网站的任何部分,导致搜索引擎不收录网站。
2、允许所有的spider抓取(或者也可以建一个空的robots.txt文件)
User-agent: *
Allow: /
以上robots规则是允许所有搜索引擎抓取网站的任何部分,但为避免错误,建议建一个空的robots.txt文件即可。
3、禁止spider抓取特定目录
User-agent: *
Disallow: /a/
Disallow: /b/
Disallow: /c/
以上例子,禁止所有的spider抓取a、b、c目录。这个规则我们最常用到,比如网站的程序后台、程序目录等都可以禁止spider抓取,以减少spider无意义的浪费我们的空间资源。
4、禁止抓取网站中所有的动态页面
User-agent: *
Disallow: /*?*
以上例子,禁止抓取网站中所有的动态页面。这个规则适用不希望spider抓取网站的动态页面。例如我们网站对动态页面进行伪静态,我们就需要设置此规则,以免spider抓取到重复的内容,影响搜索体验。
以上,是简单的robots.txt文件编写方法。可能,你还是不知道如何编写robots.txt文件,也没有关系,这时我们需要借助工具来帮助我们。
打开百度站长平台http://zhanzhang.baidu.com使用百度账号进行登录,在通用工具一栏,我们会发现Robots工具,这个工具提供了两个功能,一是检测robots.txt,二是生成robots.txt。然后我们选择生成robots.txt,User-agent选择“所有”,状态我们选择“不允许抓取”,然后在路径中填写希望不被搜索引擎抓取的目录,记得以“/”开头,然后点击创建即可完成robots.txt的生成,如图所示:
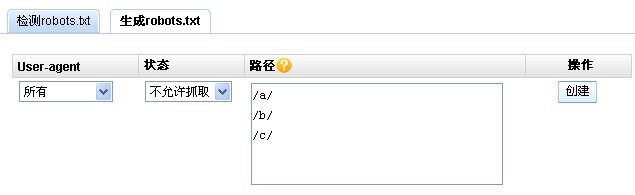
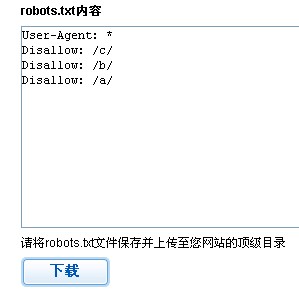
我们可以直接下载生成的robots.txt文件上传到网站根目录即可。当然我们还可以检测robots.txt文件安装、编写的正确性,还可以分析robots.txt是否符合我们的要求。我们转入robots.txt检测,输入我们的网址,如https://www.hechangquan.com/,输入验证码然后点击检测,如图所示:
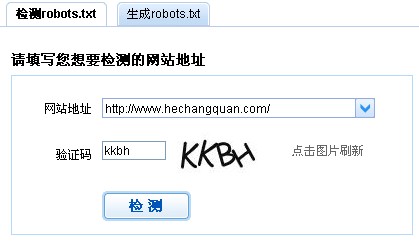

从上图我们很直观看出禁止spider抓取特定目录。
当然,上面的知识可能比较简单,没有关系,如果需要学习更多,请移步至百度帮助中心robots.txt文件编写http://www.baidu.com/search/robots.html


